RPE vs RIR for Online Coaching: Which One Actually Scales When You Have 40 Clients

Your client just texted you their RPE. Here's the problem.
It's Tuesday morning. You have 38 clients this week. Twelve check-ins are due. You open your coaching app and start at the top of the queue.
Client 7 finished her lower-body session last night. Notes field: "felt good. RPE 7." Client 23 finished his squat session. Notes: "heavy. RPE 7." Client 31, who started four weeks ago, finished her first RDL session. Notes: "hard. RPE 7."
Three RPE 7s. Zero of them mean the same thing.
One has trained two years and could have gone harder. One is a five-year powerlifter being honest about a true rep in reserve. One is a beginner who stopped because the lift felt unfamiliar, not because she was close to failure.
That's the RPE compliance problem at scale. And it's not a client problem. It's a tool-choice problem, which is why the RPE vs. RIR debate looks completely different the moment you're managing 40 async clients instead of watching one client lift in front of you.
Most coaches debate RPE vs RIR as a science question. For online coaches at scale, it's an operations question. The prescription tool that scales isn't the one that's more "accurate" in a study. It's the one your roster can execute, log, and self-correct without you in the room. Choose the prescription system your operations can support, not the one that scores higher in the literature on trained powerlifters.

Get the decision tool while you read. Download "The RPE vs RIR Selector + Roster Implementation Map", a one-page routing protocol that tags every client on your roster as Session-RPE, Full RPE, or RIR-Ready in under 20 minutes. Get the free guide →
The timing for naming this matters. In January 2026, MacroFactor Workouts launched as the first mass-market coaching app with AI suggestions expressed natively in RIR targets, aligning with the 2026 ACSM Position Stand that named "2–3 RIR" as the recommended intensity anchor for resistance training [ACSM, 2026, Medicine & Science in Sports & Exercise]. In the same quarter, CoachRx pushed a Q1 2026 update that collapsed its RPE scale from 10 points to 5, explicitly because the platform team concluded that "clients may not distinguish reliably between a 6 and a 7" on the 10-point scale. And in July 2025, the most comprehensive autoregulation meta-analysis to date (15 RCTs, networked across four methods) ranked RPE third for maximal strength on the back squat, behind APRE and ahead of percentage-based training [PMC12336695, 2025, Journal of Exercise Science & Fitness].
So the infrastructure, the research, and your clients' default tools are all moving at once, sometimes in opposite directions in the same week.
Here's what this article does. First, it walks through what the evidence actually says about RPE and RIR accuracy, including the conditions under which each tool works and the conditions under which it fails. Then it names four structural reasons coaches pick the wrong system at intake and pay for it for twelve weeks. Then it delivers a 3-factor decision protocol you can paste into your client intake form on Monday. Finally, it gives you a phase-aligned prescription map and a week-by-week implementation guide so the framework actually lands in your practice.
Hold the thesis as you read: this isn't a "both have their place" article. It's a "here's how to choose" article. The recommendation is explicit. The reasoning shows you why.
What the data actually shows: RPE and RIR accuracy evidence
The research doesn't say "use RIR" or "use RPE." It says both have accuracy conditions, and those conditions map directly onto coaching decisions you make at intake, not principles you debate in the abstract.
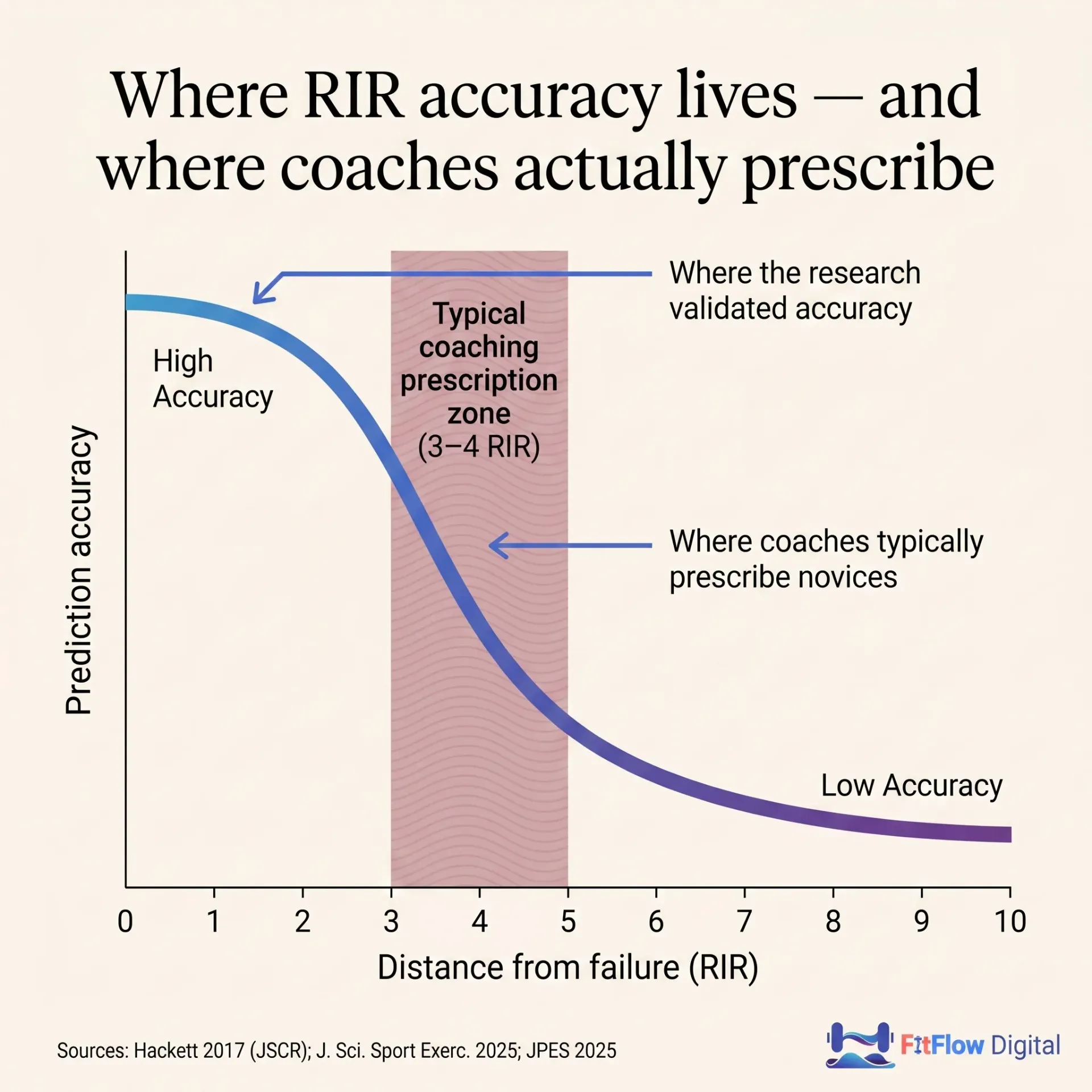
Start with RIR accuracy. Zourdos et al. (2016, JSCR) validated the RIR-based RPE scale against bar velocity in back squat performance, and in the accompanying applications paper [Zourdos et al., 2016, Strength & Conditioning Journal], laid out the framework for prescribing RIR/RPE across mesocycles. Experienced squatters showed a strong inverse correlation between velocity and reported RPE (r = −0.88). Novice squatters still showed a meaningful correlation (r = −0.77), but lower. The scale was valid, but validity varied by experience. Hackett et al. (2017, JSCR) added a critical finding: RIR accuracy is highest when the set is performed within 0–5 reps of failure. Once a client is more than 5 reps from failure, RIR estimation degrades sharply. Accuracy isn't a stable trait of the lifter. It's a function of how close to failure the set is. A 2025 RCT in the Journal of Science in Sport and Exercise confirmed this in a controlled protocol; proximity to failure was the dominant variable [J. Sci. Sport Exerc., 2025]. For coaches who prescribe 3–4 RIR in hypertrophy blocks (which is most coaches, most of the time), this is the danger zone.
Now the nuance that complicates the standard story. Remmert, Zourdos, and colleagues (2023, Perceptual and Motor Skills) found that training experience did NOT significantly affect RIR accuracy in their study population. That sounds like it contradicts everything above. It doesn't. Their protocol used single-joint exercises performed to failure at 72.5% 1RM, not multi-joint movements stopped at 2–4 RIR. When clients are taken all the way to failure on a leg extension or biceps curl, the proximity-to-failure variable is maxed out and the lifter is reading a much clearer physiological signal. A follow-up study from the same group tracked RIR prediction accuracy across six weeks of bench-press training and found that accuracy improved with repeated exposure to failure-proximate sets; calibration is trainable, but it requires the experience of getting close to failure to develop [Remmert et al., 2023, Perceptual and Motor Skills, bench-press training-effect study]. In standard online coaching, where clients stop short of failure on compound movements, the conditions that made RIR accurate in Remmert's experimental work are absent, and the calibration training that builds RIR accuracy is rarely deliberately programmed. A November 2025 study in the Journal of Physical Education and Sport tested experienced vs. novice back squatters at typical coaching intensities and recovered the expected experience-related accuracy gap [JPES, 2025]. Multi-joint, sub-failure, moderate-rep work is where the gap shows up. That's most of online coaching.
What about the broader autoregulation question? The July 2025 network meta-analysis (15 RCTs across APRE, RPE, VBRT, and PBRT) produced SUCRA rankings most coaches haven't yet seen [PMC12336695, 2025, Journal of Exercise Science & Fitness]. For maximal strength on the back squat, the order was APRE (93.0%), RPE (66.8%), VBRT (27.0%), PBRT (13.2%). For bench press: APRE (97.1%), VBRT (57.1%), RPE (29.9%), PBRT (15.9%). Two non-obvious findings here. First, percentage-based training, still the default in mass-market programming, is the worst-performing method in the analysis. Second, RPE is good but not best; APRE-style progressive auto-titration outperforms it. The Helms et al. (2018, JSCR) volume-autoregulation work pointed this direction years earlier; using RPE as a within-mesocycle adjustment tool rather than an absolute prescription was already known to outperform static %1RM. Greig and colleagues' 2021 systematic review of autoregulated training reached the same general conclusion across a smaller evidence base [Greig et al., 2021, Sports Medicine]. Bastos and colleagues' 2024 scoping review of RIR-scale feasibility reinforces a separate operational finding most coaches don't internalize: RIR is feasible across a wide range of populations and exercises, but feasibility and accuracy are different things [Bastos et al., 2024, Perceptual and Motor Skills]. The 2025 meta-analysis confirmed the autoregulation-over-percentages story at scale.
And the institutional shift. The 2026 ACSM Position Stand (the first update since 2009, built from 137 systematic reviews and over 30,000 participants) explicitly recommends 2–3 RIR as the primary intensity anchor for resistance training, and confirms that training to muscular failure isn't superior to stopping short for either strength or hypertrophy [ACSM, 2026, Medicine & Science in Sports & Exercise]. The governing body now endorses RIR-language for intensity prescription. That isn't a small institutional move. It's the same body that resisted percentage-based prescription reform for two decades.
The accuracy-and-scalability picture across conditions:
Condition | RIR Accuracy | RPE Suitability | Coaching Implication |
|---|---|---|---|
Client: 24+ months training, 1–5 rep strength work | HIGH | HIGH | Either tool works; RPE captures systemic fatigue better; RIR is more precise |
Client: 24+ months, 6–15 rep hypertrophy | MODERATE (4+ RIR = degraded) | MODERATE | RIR is less reliable in the moderate-RIR zone; session-level RPE may be more robust |
Client: 6–18 months training, any rep range | LOW–MODERATE | MODERATE | RIR at 3–4 may drift by ±2–3 reps; use simplified RPE; recalibrate monthly |
Client: under 6 months training | LOW | LOW–MODERATE | Neither tool is calibrated; use 3–5 point session RPE; run calibration set at month 2 |
GLP-1 medication client | UNCERTAIN | UNCERTAIN | Altered fatigue perception; use simplified session RPE; establish pre-medication baseline |
Deload week, any client | LOW (drift documented) | MODERATE | Clients underestimate effort during deloads; use session RPE not set-level RIR |
The data supports RIR as valid AND accurate, but only under specific conditions. The problem isn't that RIR is wrong. The problem is that online coaching at scale produces conditions where those specific conditions are the exception, not the rule.
The scalability lens: the operational criteria the literature ignores
The studies that validated RPE and RIR were run with supervised subjects who had researchers (or coaches) watching every rep. The conditions of online coaching (async check-ins, self-reported data, diverse training ages, no direct observation, batches of 30–50 clients per coach) are almost never modeled in the research. The scalability lens is the framework the literature can't give you. You have to build it.
Scalability factor 1, logging friction per session. RPE on a 0–10 scale produces one number after a session. A client can report it at the end of the workout, with no mid-set cognition. The CoachRx Q1 2026 simplification to a 5-point scale was a tacit admission that even one number is too granular, but the architecture is still one entry, post-session. RIR is different. Set-level RIR requires the client to predict remaining reps before each set ends. That's a specific mid-set cognitive process. Across a five-set squat block, the client is producing five separate predictions, each requiring an internal model of how many reps they have left on a partially fatigued muscle. The friction is genuinely higher. Multiple data points per session vs. one post-session number isn't a small difference at the compliance level. It's the difference between meaningfully higher and meaningfully lower logging rates in client populations who are also juggling work, kids, and a 5 a.m. session.
Scalability factor 2, novice calibration error rate. If 60% of a remote coach's client book has under 18 months of training experience (the median for most online coaches building toward 40 clients), and those clients are prescribed 3–4 RIR in a hypertrophy block, they're operating in the lowest-accuracy zone of the RIR scale: far from failure, on multi-joint movement, with limited proximity-to-failure reference points. The error margin in the literature is estimated at ±2–3 reps. A 3 RIR prescription becomes anywhere from a 1 RIR (dangerously close to failure, possible form breakdown, real injury risk) to a 6 RIR (insufficiently stimulative, below the hypertrophy threshold for the day). Across a 20-novice slice of your roster, you have systematic variance you can't observe and can't correct without additional check-in overhead. Session-level RPE for novices captures holistic effort without requiring precision prediction. A client can answer "that felt like an 8 out of 10" as a gestalt judgment they can make without formal training. RIR requires a specific cognitive skill: mental representation of how many concentric reps remain on a fatigued muscle. That skill requires calibration training.
Scalability factor 3, async coachability. How easily can a coach interpret and act on the client's data without a real-time conversation? Session-level RPE produces one number, post-session. If the expected RPE was 7 and the client reported 9, the coach knows immediately: the session was harder than planned. No conversation required. The signal is clear, and the coach can intervene at the program-design level without back-and-forth. Set-level RIR produces multiple data points per session. When accurate, it's more informative. But noise (calibration error, compliance gaps, mid-set distraction, the client checking a notification between sets) contaminates the signal. A coach interpreting 12 sets of RIR data per workout, across 30 clients, every week, isn't scaling. That's data entry on the coach's side, dressed up as data collection on the client's side.
Scalability factor 4, roster audit time per client per week. Reviewing and responding to session-level RPE across 40 clients runs about 8–12 minutes per client per week (roughly 90 seconds per check-in across 4–6 sessions, plus 2–3 minutes per flagged session). At 40 clients, that's 5.5 to 8 hours per week on intensity monitoring alone. Interpreting multi-set RIR data adds an estimated 20–30% overhead, another 1–2 hours per week at the same roster size. Even at the low end, that extra hour compounds to 52 hours per year, every year. The intensity tool you standardize has a measurable effect on the time budget you actually have to coach. That's the operational math the literature doesn't run.

This is the part of the decision the research doesn't model. It's also the part that determines whether your coaching practice can grow from 15 clients to 40 without buying you out of your own evenings.
The 4 failure modes: why coaches pick the wrong system
Coaches who are frustrated with RPE or RIR compliance are almost never frustrated because they're uninformed. They're using the wrong tool for one of four structural reasons that have very little to do with what the research says.
Failure mode 1: tribal default, not roster fit
The powerlifting community (RTS, JuggernautAI, Calgary Barbell) uses RPE. The bodybuilding and hypertrophy community (RP Strength, Dr. Mike Israetel's content) uses RIR. If you were trained in either ecosystem, you absorbed the tribal default before you ever sat down to evaluate it against your actual client book. The problem is that most online coaches build books that include neither population. A coach who specializes in general-population female body composition, hybrid endurance-strength athletes, or GLP-1 medication clients inherited an intensity language designed for an elite-leaning sliver of the lifting world. The default was selected for the loudest community, not for the roster you actually have.
Failure mode 2: platform default, not deliberate choice
The platform chose for you. Trainerize auto-prompts post-session RPE. Hevy logs set-level RPE on a 6–10 scale and doesn't surface RIR as a separate field. MacroFactor Workouts, launching in January 2026, was built RIR-native, and a coach whose clients adopted it as their self-tracking app inherited an RIR-native vocabulary they may never have chosen. JuggernautAI is RPE-native and has been since 2024. Coaches who picked a coaching platform before they thought about intensity prescription are using whatever the platform's onboarding flow nudged them toward. Sometimes the alignment is correct. Often it's accidental. Few coaches have audited it.
Failure mode 3: no client-book demographics audit
RPE vs. RIR works differently across training age, rep range, and goal. A coach with 40 clients spanning novices, intermediates, and advanced athletes needs a differentiated approach, not a single-tool blanket prescription. Most coaches have never done a training-age audit of their book. They don't know what percentage of their clients sit in the RIR danger zone (under 18 months training experience, prescribed 3–4 RIR on compound hypertrophy work). Until you've run the audit, you're guessing whether your tool fits your population. The guess is usually wrong in the direction of the trainer's own training age, not the client's. The framework I run inside the 30-client wall operations playbook explicitly names this audit as one of the gating systems a coach must install before scaling past 25 clients.
Failure mode 4: "valid in research" mistaken for "scalable in practice"
The research that validated RPE and RIR was conducted on supervised, in-person populations with substantial training experience. The conditions that make RIR accurate (close to failure, familiar movement, prior calibration, observation) are NOT the conditions of most online coaching check-ins, where clients stop short of failure, are self-supervised, and may not have a precise internal model of what their failure point feels like on the exercise in question. A tool validated in the lab for one population fails in the field for a different one. This isn't a research flaw. It's an application flaw, the same systems flaw at the center of our argument that the training program is rarely the problem; the system around it is. Strong tools in weak systems produce weak outcomes.
These four failure modes are structural. Naming them is step one. The decision protocol below removes them from your practice.
The decision framework: the 3-factor protocol
Halfway through. Download the Selector + Roster Implementation Map. It converts this exact 3-factor protocol into a one-page tool you can complete for your entire client roster in 20 minutes.
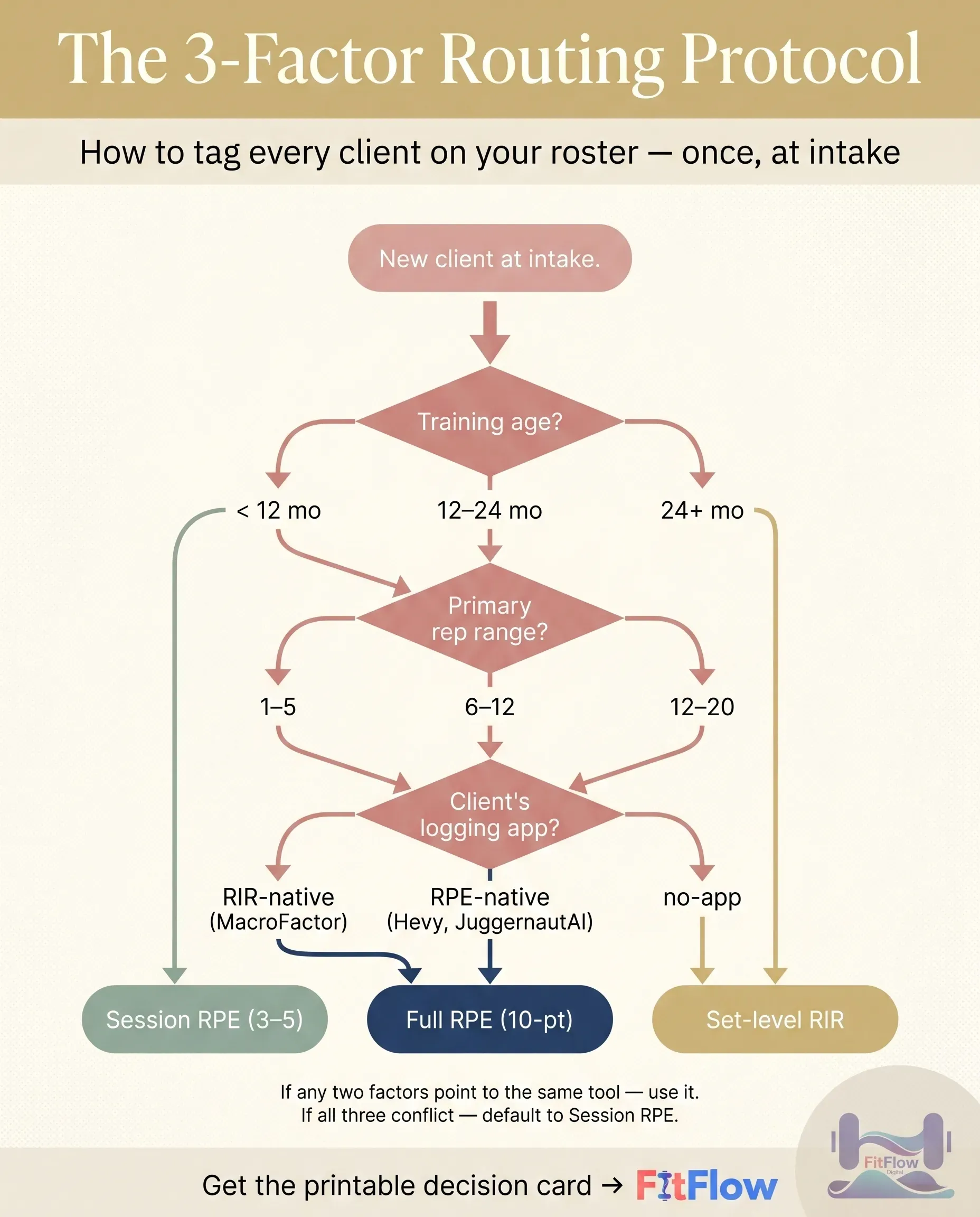
The framework doesn't replace your judgment. It structures it. Score each client on three factors at intake. If any two factors point to the same tool, use it. If all three conflict, default to session-level RPE. Run the protocol once at intake; revisit at the 6-week mark.
Factor 1: training age
Training Age | Default Tool | Rationale |
|---|---|---|
Under 12 months | Session-level RPE (3–5 point simplified scale) | Neither RIR nor full 10-point RPE is calibrated; simplified scale captures effort without requiring precision prediction |
12–24 months | Session-level RPE (10-point) OR set-level RIR with calibration onboarding | Client may have enough experience for RIR to be reliable in low-rep ranges (≤6 reps); use RIR only if a solid failure-proximity reference exists |
24+ months | Set-level RIR (hypertrophy) OR RPE (strength/low-rep) | Both tools are reliable; choose based on rep range and platform |
Factor 2: rep range
Rep Range | Default Tool | Rationale |
|---|---|---|
1–5 reps (strength/low-rep) | RPE 7–9 | Low-rep work is typically close enough to maximum effort that RPE captures systemic strain accurately |
6–12 reps (hypertrophy/moderate) | RIR 2–4 (24+ months) OR Session RPE (novice/intermediate) | The accuracy zone shifts with training age; see Factor 1 to break ties |
12–20 reps (high-rep / metabolic) | Session-level RPE | Holistic effort is the cleaner signal; set-level reporting is burdensome at high-rep endurance work |
Factor 3: platform native language
Client's Primary App | Coach Action | Why |
|---|---|---|
MacroFactor Workouts (Jan 2026, RIR-native) | Match with RIR prescription | Vocabulary alignment reduces translation friction |
JuggernautAI (RPE-native) | Match with RPE prescription | Readiness questionnaires and per-set RPE are the native log fields |
Hevy (RPE, set-level, 6–10) | Match with RPE prescription | Largest single overlap with general-population client books; RIR isn't a separate field |
CoachRx (1–5 simplified RPE) | Match with CoachRx's 1–5 scale | Platform's built-in effort tracking is the default; align with it |
Trainerize (post-session RPE) | Use session-level RPE | Architecture is session-level; set-level RIR creates a logging gap |
No dedicated app / self-tracked | Session-level RPE (3–5 scale) | Lowest friction; reportable via text or voice memo |
The protocol in one sentence: score each client on all three factors at intake. If any two factors point to the same tool, use it. If all three conflict (rare in practice), default to session-level RPE, which is the lowest-friction fallback across every segment.
Two-of-three majority isn't intrinsically magical. What works is that all three factors are independent gates on the same scalability problem: tool fit (Factor 1), task fit (Factor 2), and platform fit (Factor 3). Misaligning one is recoverable. Misaligning two is the failure-mode pattern named above. The protocol turns the failure modes into a positive checklist.
Phase-aligned prescription map
The 3-factor protocol tells you which tool to use per client. The phase-aligned map tells you how to adjust within a mesocycle as the intensity demands shift.
Training Phase | Rep Range | Recommended Tool | Intensity Target | Watch For | Roster Audit Signal |
|---|---|---|---|---|---|
Hypertrophy / Accumulation | 6–15 | RIR 2–4 (24+ months) / RPE 7–8 (intermediate) | 65–80% 1RM | RIR accuracy degrades in weeks 3–4 as fatigue accumulates | 3+ clients reporting "felt easy but RIR logged as 3" = recalibration trigger |
Strength / Intensification | 1–5 | RPE 7–9 | 80–95% 1RM | Systemic fatigue elevation in week 3–4 | 3+ clients missing target RPE by ≥1 point for 2+ sessions = deload trigger |
Recomp | 8–15 | RPE 6–8 (session) | 55–75% 1RM | NEAT compensation may shift baseline effort | RPE trending up across roster without load change = nutrition or NEAT review |
GLP-1 medication clients | Any | Session RPE (3–5 simplified) | Per client | Altered fatigue perception; systematic underreporting | Significant RPE drop without training-load reduction = clinical coordination flag |
Novice onboarding (under 12 months) | Any | Session RPE (3–5) + calibration set at month 2 | Not load-dependent | Social-desirability bias clustering at 7 or 8 | RPE clustered at 7–8 across all clients = scale isn't being used honestly |
Deload week | 40–60% normal | Session RPE (target 5–6) | N/A (intentional underload) | RIR drift; clients underestimate effort during deloads | Any deload session RPE > 7 = load too high OR client not deloading |
The deload RIR drift problem
This one deserves a callout. RIR drift during deloads shows up in the evidence base and is consistently underestimated by coaches.
During a deload, a client who normally squats at 80% 1RM may be prescribed 60% 1RM for the same rep range. The client stops at what feels like "3 RIR," but because the absolute load is much lower, their actual proximity to failure on the lighter weight may be 8–10 reps, not 3. They aren't logging RIR; they're logging "felt like 3 reps' worth of effort," which is a different thing. The result: deload sessions often aren't actually easy enough, accumulated fatigue doesn't fully dissipate, and the subsequent intensification block underperforms.
Session-level RPE (target 5–6 out of 10) is more reliable for deload prescription because it captures holistic effort, not failure-proximity prediction.
The novice calibration protocol: the week-6 milestone
For clients under 18 months training experience, run this calibration check at the 6-week mark:
Assign a set to failure on a secondary exercise with low injury risk (machine row, leg press, biceps curl).
Have the client predict RIR before the set starts ("I think I have 4 reps left").
Have the client perform the set to muscular failure.
Compare predicted vs. actual RIR.
If the gap is ≤ 2 reps: client is ready for set-level RIR programming.
If the gap is ≥ 3 reps: continue session-level RPE for another 4–6 weeks; repeat calibration check at week 12.
This is what the literature calls proximity-to-failure reference-point training. It's the fastest documented method to calibrate RIR accuracy in newer trainees [Remmert et al., 2023, Perceptual and Motor Skills].
Platform vocabulary alignment: matching your language to your client's app
The platform your client uses for workout logging has already voted on the RPE vs. RIR question. Ignore that vote at your compliance peril.
Platform | Native Intensity Language | Set or Session Level | Status (2026) | Coach Action |
|---|---|---|---|---|
MacroFactor Workouts | RIR (AI suggestions in RIR) | Set-level | Jan 2026 launch | Prescribe RIR for MacroFactor users |
JuggernautAI v2.5 | RPE (readiness + per-set) | Set-level | 2024–2025 | RPE-native; prescribe RPE |
Hevy / Hevy Coach | RPE (6–10, set-level) | Set-level | 12M+ users active | Largest overlap with general-pop client books |
CoachRx (OPEX) | Simplified RPE (1–5 → 1–10) | Session or set | Q1 2026 update | Match the 5-point framework |
Trainerize (ABC) | RPE (post-session) | Session-level | 2023–2025 | Set-level RIR creates a logging gap |
TrueCoach | RPE (set-level, toggle) | Set-level | 2025 | Native RPE notation; use set-level RPE |

The January 2026 vocabulary split is the part of this most coaches haven't metabolized. MacroFactor (built by the Stronger by Science team, explicitly aligned with the ACSM 2026 RIR-language stance) launched at the same moment JuggernautAI and Hevy (two of the largest training platforms by active users) remain RPE-native. A coach who prescribes one system uniformly across a 40-client book that includes both MacroFactor and Hevy users is producing translation friction for roughly half the roster, every week, for no benefit.
The intake fix: add one question to your CRM or onboarding form: "Which app do you primarily use to log your workouts?" Tag each client as RPE-native or RIR-native based on the answer. That tag is Factor 3 in the decision protocol. It takes ninety seconds at intake and saves five minutes of translation in every weekly check-in for the entire client relationship. Our cluster post on the single most ignored factor in client results makes the same operational point with NEAT: the data is already there; the protocol isn't.
Two-client case study: same coach, same program, different tools
The difference between a scaled coaching practice and a burned-out one is often the intensity-prescription tool that was chosen in week one of onboarding, before either coach or client realized it mattered.
Same coach. Same 12-week hypertrophy program. Client A and Client B started within a week of each other. Near-identical starting profiles: 19 months training experience, 3x/week online coaching, similar body composition goals, similar weekly check-in cadence. The only difference was the intensity tool assigned at intake.
Composite case built from common coaching-practice patterns; not a single client record.
Client A: set-level RIR, no calibration protocol
Weeks 1–2. Client completes check-ins, logs RIR per set. Notes: "3 RIR, 3 RIR, 4 RIR, 2 RIR" across four working sets. Coach reads the data and bumps load upward in week 2. So far, the system is working as designed.
Weeks 3–4. Client is noticeably fatigued. Deload isn't due yet. Coach reviews logs. RIR still shows 2–3. Coach encourages client to push more. The actual sets were at 5–6 RIR. The client had been rounding their estimates down because they weren't sure how to interpret the gap and didn't want to under-deliver on the prescription. The data was always wrong; the conversation was diagnosing the symptom.
Week 6. Client stalls on a squat 1RM attempt. Coach interprets the stall as a volume issue and pulls volume down. The actual problem was insufficient stimulus for three weeks driven by RIR calibration error in the hypertrophy block.
Week 12. Client gains 3% on primary strength metrics, well below the 8–10% the program was designed to deliver. Coach spends an estimated extra 2.5 hours over twelve weeks investigating compliance issues that were never compliance issues. Client renews at the next quarter but cancels two months later.
Client B: session-level RPE + month-2 RIR calibration
Weeks 1–2. Client logs session RPE: 9, 8, 7, 8 across four sessions. Simple signal: sessions are appropriately hard; the slight decrease in session three matches scheduled fatigue. No follow-up required.
Weeks 3–4. Session RPE trends upward without a load change. Coach flags the pattern: client is working harder for the same load, which is the deload signal. Coach pulls deload forward by one week. Total coach decision time: about 90 seconds, anchored to one trend line.
Week 6 calibration protocol. Client performs an RIR prediction on a leg press set to failure. Predicted 3 RIR; actual 4 RIR. Within the ≤2-rep accuracy threshold. Coach transitions lower-body work to set-level RIR from week 7 onward.
Week 12. Client gains 9% on primary strength metrics, in line with program expectations. Coach time on intensity monitoring across the full twelve weeks: roughly 12 minutes total (about 90 seconds per check-in, with two flagged sessions). Client renews for six more months and refers a friend.
The outcome comparison:
Metric | Client A | Client B |
|---|---|---|
Week-1 intensity tool | Set-level RIR (immediate) | Session-level RPE (10-point) |
Calibration protocol | None | Week-6 milestone check |
Compliance with logging | 85% (some sessions skipped) | 97% (one number per session) |
Strength gain (12 weeks) | 3% | 9% |
Coach time on intensity monitoring | ~2.5 hours over 12 weeks | ~12 minutes over 12 weeks |
Client satisfaction outcome | Cancelled at month 4 | Renewed 6 months, 1 referral |
"The RPE vs RIR Selector + Roster Implementation Map" — the 3-factor protocol from this article, on one page, ready for Monday morning. Tag every client in 20 minutes. Save the 78 hours per year you'd spend investigating symptoms that aren't compliance problems. Get the Printable Card →
The lesson isn't that RIR is bad. The tool was misaligned with the client's profile and the coach's operations. Same coach, same program, two outcomes, separated by a 5-minute decision at intake that compounded for the entire client relationship.
This is the same structural insight that the analysis of why most hypertrophy programs fail after six weeks names from the program-design angle: programs don't fail because the principles are wrong; they fail because the operating system around them, including the intensity language, is mis-specified for the population.
Week 1 to week 4 implementation: onboarding the right system
Most coaches read a comparison like this and change nothing because they don't know where to start. Here's the four-week implementation that converts the framework into your operating practice.
Week 1: audit and tag your existing client book
Pull your client list. For each client, score them on the three factors: training age (under 12, 12–24, or 24+ months), primary rep range, platform native language. Tag each client with one of three labels: Session-RPE, RIR-ready, or Transition-at-calibration. Download the RPE vs RIR Selector + Roster Implementation Map, the one-page tool that systematizes exactly this audit. No program changes this week. Audit only.
Week 2: standardize onboarding for new clients
Update your intake form. Three new questions: "How long have you been training consistently?" (training age), "What workout app do you primarily use to log sessions?" (platform), and "Have you used RPE or RIR in programming before?" (calibration baseline). Map each combination of answers to the tool using the 3-factor decision protocol above. Write a 150-word "Intensity Prescription Introduction" for each tier (Session-RPE, RIR-ready, Transition) that you can paste into the welcome message of every new client.
Week 3: introduce the tool to your existing book
For Session-RPE clients: "Starting this week, we're tracking one extra data point: how hard each session felt on a scale of 1–10. This takes ten seconds after the workout. Here's what each number means: [attach RPE reference card]." For RIR-ready clients: "We're adding RIR tracking to your sets this week. After each working set, note how many reps you think you had left. Here's the quick reference card from the evidence-based program design guide." Expect 60–80% compliance in week one. Don't over-correct. The first two weeks are calibration, not data.
Week 4: review, adjust, and set the 6-week calibration checkpoint
Review session RPE trends across the roster. Flag any clients consistently below 6 (undershooting) or above 9 (consistently training too hard). For RIR-using clients, compare logged RIR against your prescribed range; if more than three clients are logging RIR outside ±1 of prescription, the prescription is calibrated wrong, not your clients. Set a 6-week calibration checkpoint reminder for every client in the "under 18 months training" segment.
A note for Amanda, the coach building a first 10–20 clients. Default to session-level RPE (3–5 scale) for everyone for the first six weeks. The simplest tool that produces reliable data is the correct tool. Graduate to full RPE or set-level RIR as clients demonstrate calibration accuracy at the week-6 checkpoint. Don't try to operate a differentiated tool system at under ten clients. The overhead isn't worth the precision gain. The same logic shows up in the 80/20 of training results: premature complexity at small scale is the most common reason new coaches stall their own growth.
Your next steps
You now have the framework. Here's how to put it into practice this week.
Download the "RPE vs RIR Selector + Roster Implementation Map." The decision guide takes the 3-factor protocol from this article and converts it into a one-page tool you can complete for your full client roster in 20 minutes. Every client gets tagged: Session-RPE, Full RPE, or RIR-Ready. Every transition trigger is mapped. Every platform native language is in the table. Get the free decision guide →
Three follow-up reads from the cluster:
For the evidence foundation and the existing RPE/RIR Quick Reference Card, start with Evidence-Based Program Design — The Complete Reference. If you want the full autoregulation evidence base referenced through this article, that's the source post.
For the next operational layer, read Your Training Program Is Not the Problem — Your System Is. Even the correct intensity tool fails inside a broken coaching system. If intensity compliance is your symptom, that post diagnoses whether the system is the disease.
For the broader online-coaching operations frame this decision sits inside, see The Operations Playbook for Online Coaches Hitting the 30-Client Wall. The intensity-tool decision is one of seven systems-level decisions that determine whether your practice scales past 30 clients without burning you out.
The framework isn't the work. The audit is. Run it this week. Re-read this article in 30 days, after the four-week implementation has rolled through your book. The next time a Client 7, a Client 23, and a Client 31 all log "RPE 7" on the same Tuesday morning, you'll already know which one needs a conversation and which two can wait.
Frequently Asked Questions
Comments